Understanding OASS
Basic Theory
Optimal Action Space Search (OASS) is an algorithm for path planning problems on directed acyclic graphs (DAG) based on reinforcement learning (RL) theory. This document will help you understand the basic theory of OASS.
First we need to clarify what a directed acyclic graph is. A directed graph 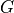 is usually defined as the set of vertices (nodes) and edges, i.e.
is usually defined as the set of vertices (nodes) and edges, i.e. 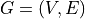 , where
, where 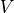 is the set containing all vertices,
is the set containing all vertices, 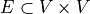 is the set of all edges. For example, the following figure is an example of a directed graph.
is the set of all edges. For example, the following figure is an example of a directed graph.
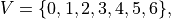
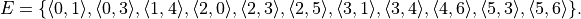
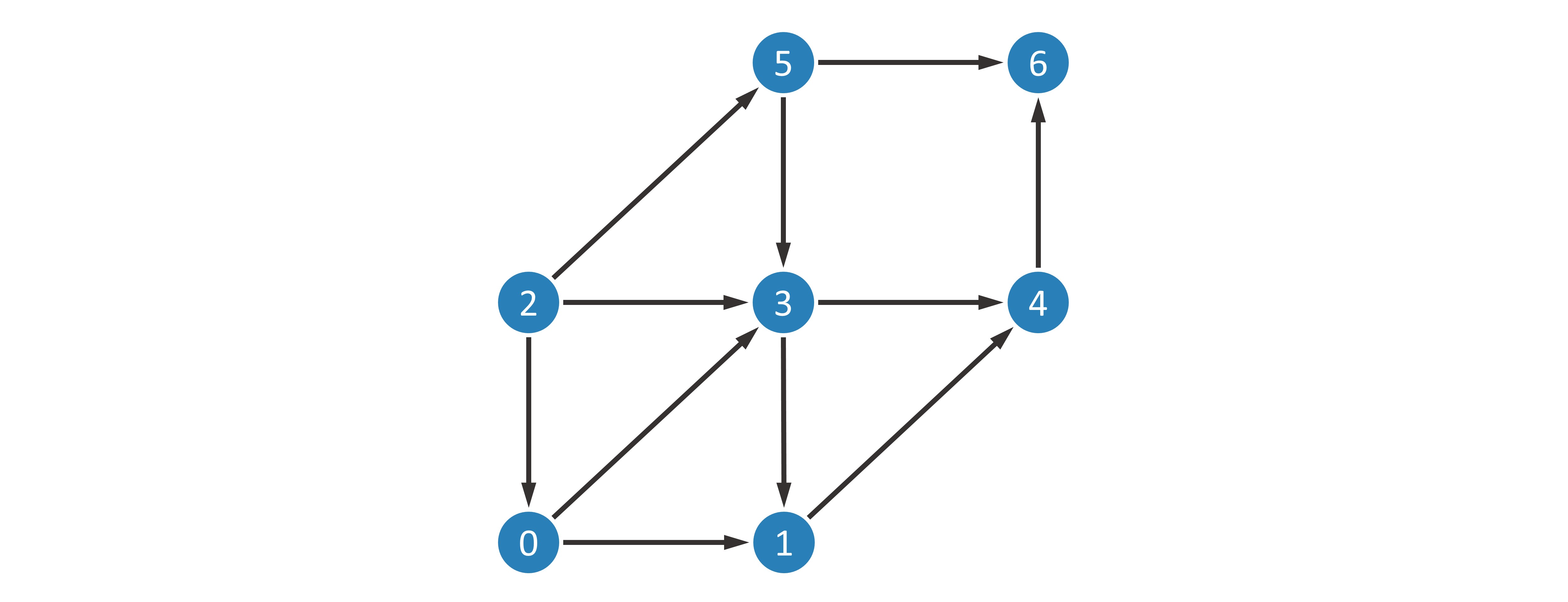
As for directed acyclic graphs, they are directed graphs without loops. Of course, the above example is also a directed acyclic graph. In addition, we add a reward to each node and each edge. Use 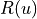 to denote the reward obtained when arriving at node
to denote the reward obtained when arriving at node 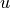 , and
, and 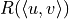 to denote the reward obtained when passing through edge
to denote the reward obtained when passing through edge 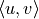 . We want to find a path
. We want to find a path 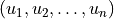 such that the sum of the rewards obtained when passing through this path is maximized, i.e.
such that the sum of the rewards obtained when passing through this path is maximized, i.e.
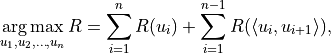
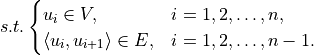
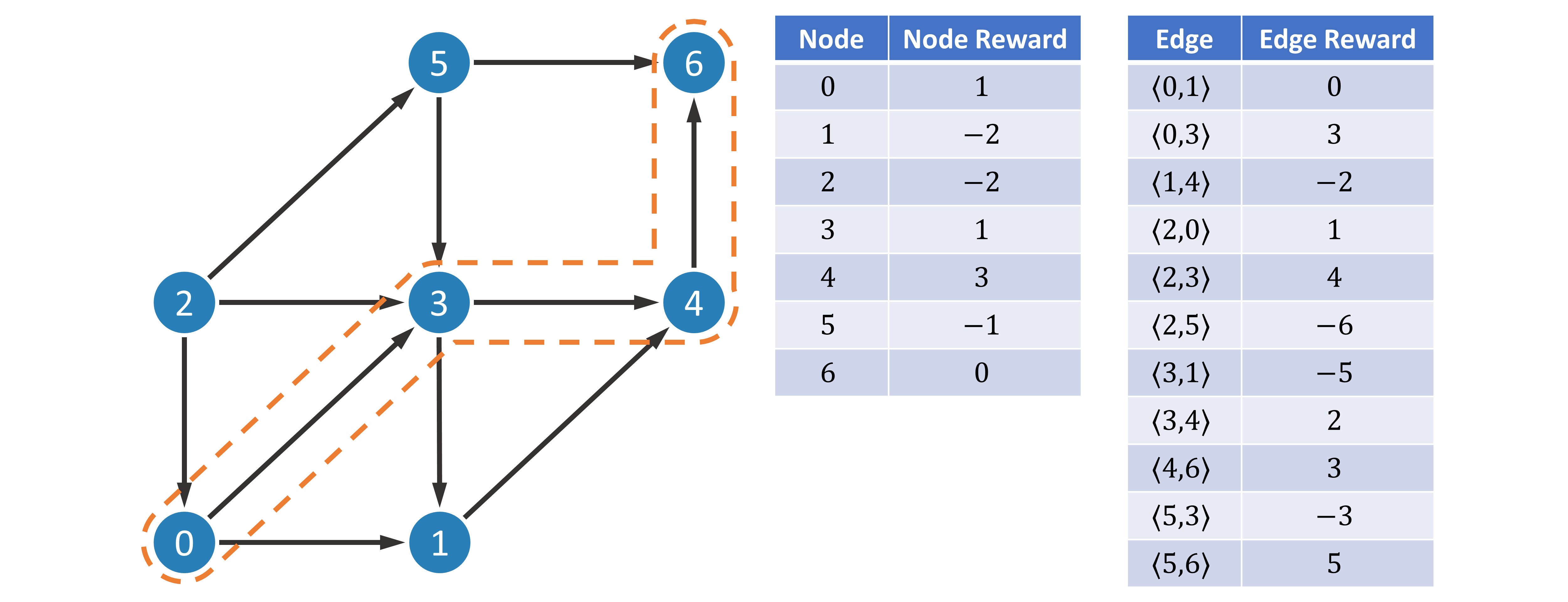
This is just an algorithmic problem and is not difficult to solve. First we perform topological sorting. Topological sorting is to sort all nodes so as to ensure that: if edge exists, then node ranks in front of  in the sorting result. The topological sort is simple: find the node with entry degree
in the sorting result. The topological sort is simple: find the node with entry degree 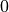 (the node without any edge pointing to it), then delete it, and repeat the process.
(the node without any edge pointing to it), then delete it, and repeat the process.
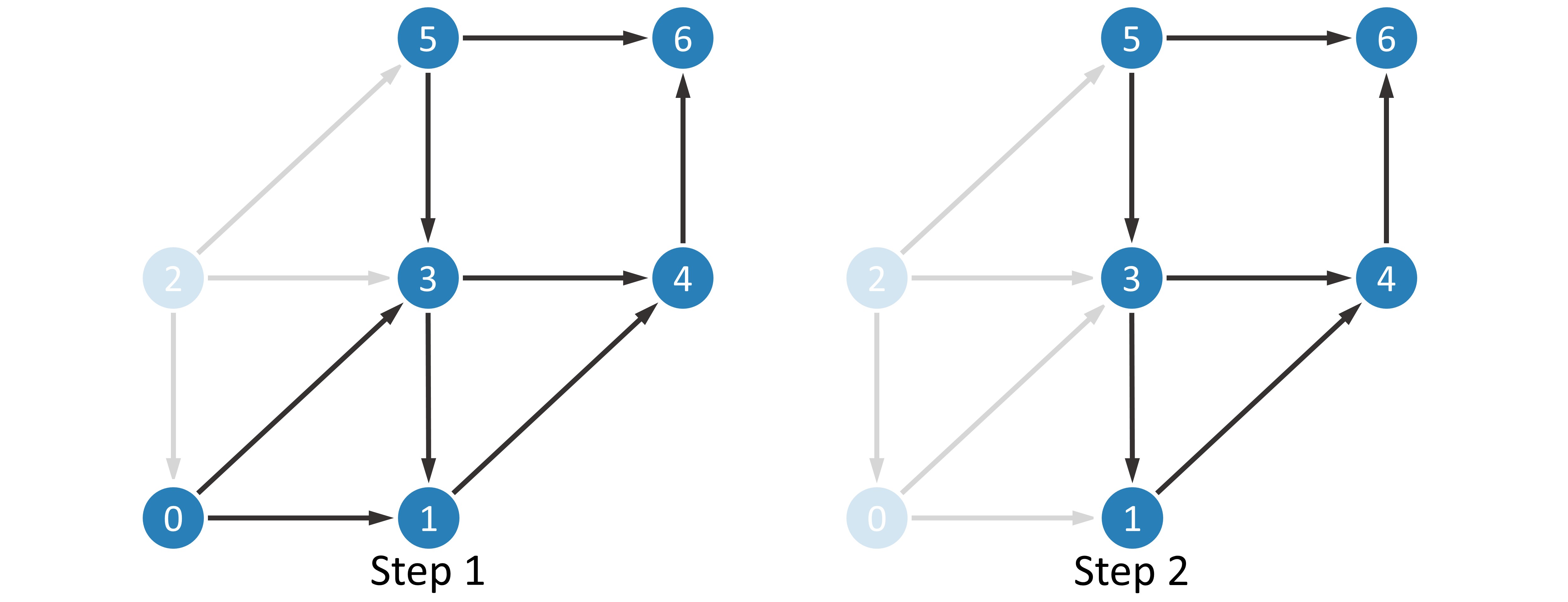

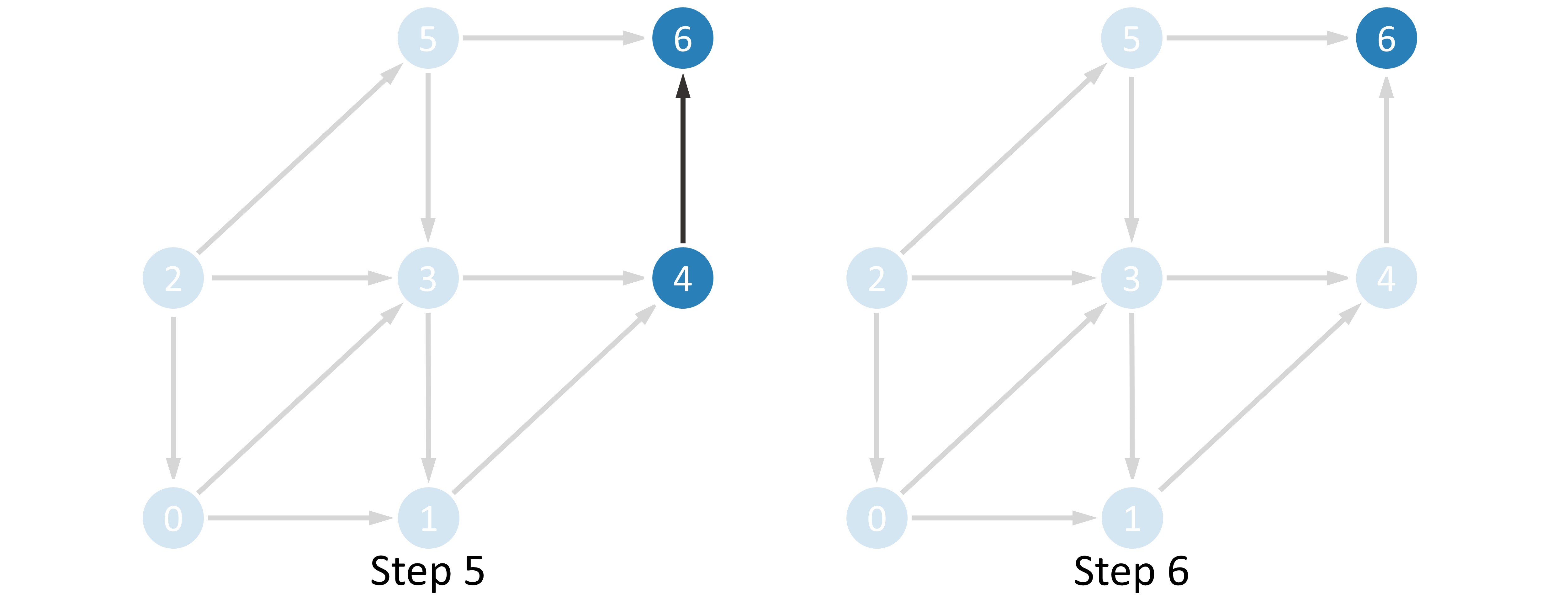
Record the order in which these nodes are deleted, which is the result of the topological sort.
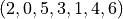
Note
If there are no nodes with entry degree
in a particular step, it means that there is a ring in this graph.The result of topological sorting is not unique. Notice that after the first step, the entry degree of both node
and node 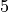 is , so it is also reasonable to delete node in the second step.
is , so it is also reasonable to delete node in the second step.
Next, we denote by 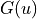 the subsequent rewards obtained when starting at and by
the subsequent rewards obtained when starting at and by 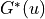 the maximum value of provided that the optimal strategy is adopted, excluding the rewards obtained when arriving at node and before that. Obviously, a dynamic programming algorithm can be constructed using a simple state transfer equation.
the maximum value of provided that the optimal strategy is adopted, excluding the rewards obtained when arriving at node and before that. Obviously, a dynamic programming algorithm can be constructed using a simple state transfer equation.
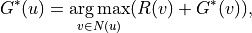
where 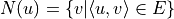 denotes the set of nodes that can be reached in one step starting from node . The premise of using this formula to compute the optimal strategy is that
denotes the set of nodes that can be reached in one step starting from node . The premise of using this formula to compute the optimal strategy is that 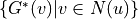 has been computed before computing . It is only necessary to compute the results in reverse order according to the topological ordering.
has been computed before computing . It is only necessary to compute the results in reverse order according to the topological ordering.
This is a very simple problem, isn’t it? But note that being able to do so assumes that we can see the complete graph structure. If at each node we can only observe a little bit of information 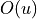 , consider constructing a strategy using some neural network structure
, consider constructing a strategy using some neural network structure 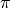 . We use
. We use 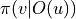 to denote the probability of the next move to node , and of course
to denote the probability of the next move to node , and of course
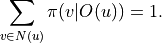
If the strategy is strong enough, it is possible to achieve 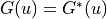 . We compute the mathematical expectation
. We compute the mathematical expectation 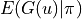 based on the strategy .
based on the strategy .
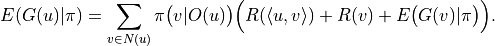
In a similar way, the results are calculated in reverse order according to the topological sort.
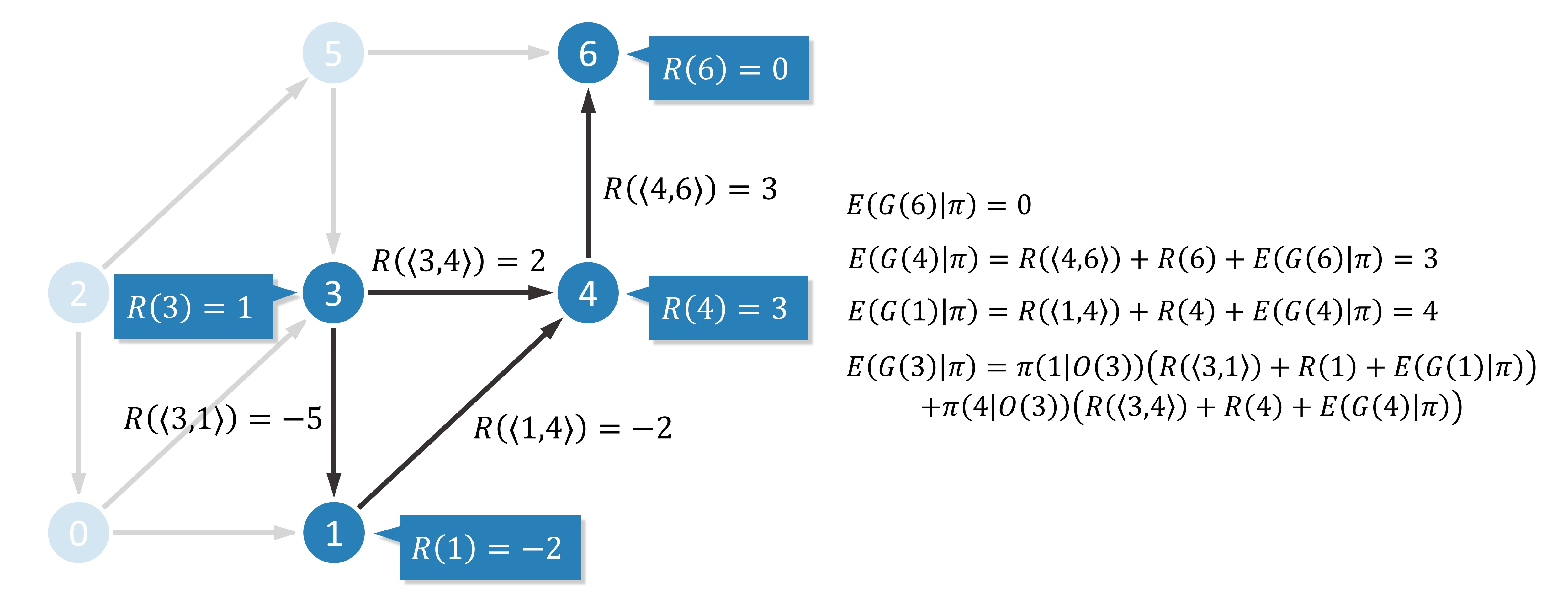
We want to make as large as possible. Since a neural network model is used, using a gradient-based optimization algorithm is a feasible solution. cannot be utilized as a loss function because it relies on the value of 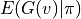 , which may cause the gradient calculation to be complex and slow. To avoid this pitfall, we directly treat as a constant and perform single-step optimization.
, which may cause the gradient calculation to be complex and slow. To avoid this pitfall, we directly treat as a constant and perform single-step optimization.
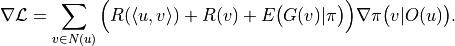
In other words, the coefficients 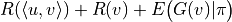 can be directly passed as gradients to the output layer
can be directly passed as gradients to the output layer 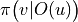 of the neural network for optimization.
of the neural network for optimization.
Integration with Reinforcement Learning Theory
The above theory is not enough to build a robust algorithm, but also needs to refer to modern reinforcement learning theory for more refined adjustment. The final gradient formula is
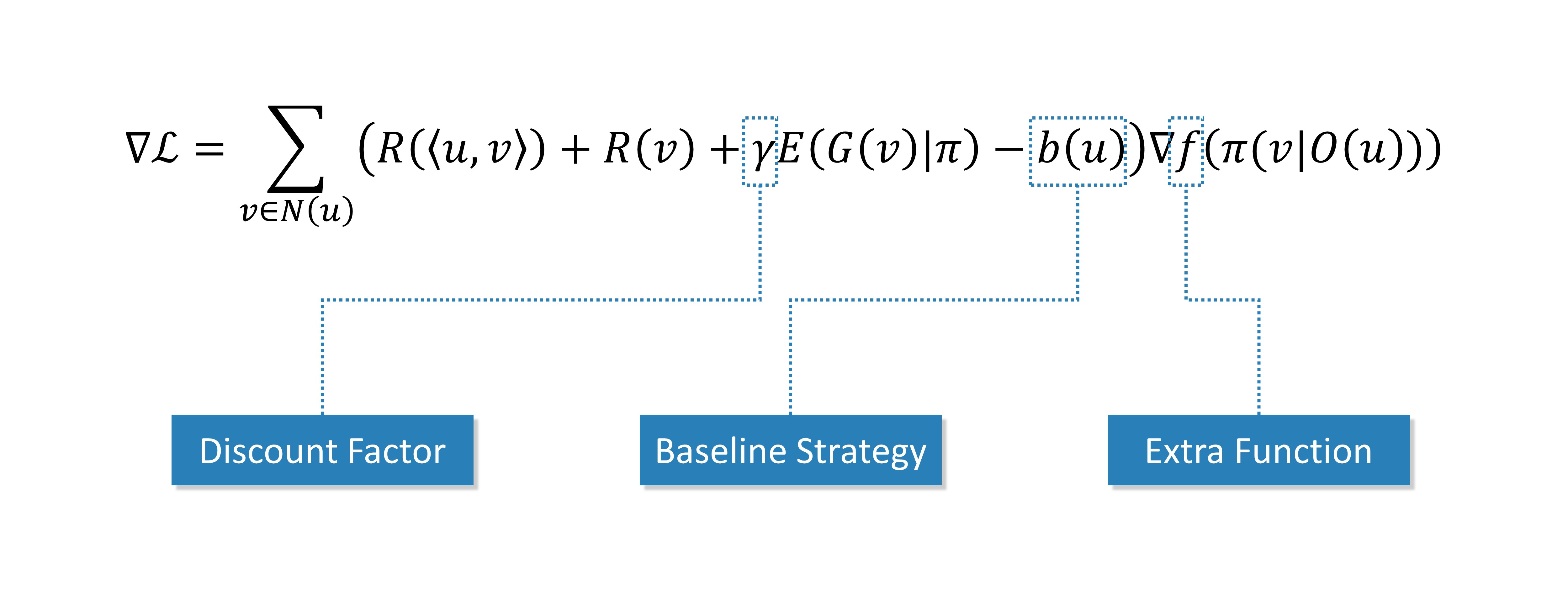
Discount Factor
In modern reinforcement learning theory, the reward function usually carries a discount factor ![\gamma\in [0,1]](../_images/math/cec1a02777451d174a26a4ebd7e63173f29840f6.png) , i.e.
, i.e.
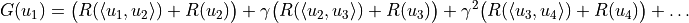
When 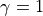 , it is exactly the same as described in the previous section. When
, it is exactly the same as described in the previous section. When 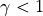 , i.e., short-term rewards are considered more important than future rewards. We set the discount factor to a customizable hyperparameter, but we still do not recommend using values other than
, i.e., short-term rewards are considered more important than future rewards. We set the discount factor to a customizable hyperparameter, but we still do not recommend using values other than 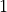 , as this may cause the OASS method to not perceive the distant rewards.
, as this may cause the OASS method to not perceive the distant rewards.
Baseline Strategy
Noting that the range of values of the coefficients depends on the definition of 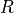 , we want to better guide the strategy to update in the direction of improvement, and therefore introduce the baseline in reinforcement learning. The coefficient after adding the baseline is usually referred to as the advantage function in reinforcement learning. A positive value indicates that increasing the corresponding probability value results in more reward, and a negative value indicates that decreasing the corresponding probability value results in more reward.
, we want to better guide the strategy to update in the direction of improvement, and therefore introduce the baseline in reinforcement learning. The coefficient after adding the baseline is usually referred to as the advantage function in reinforcement learning. A positive value indicates that increasing the corresponding probability value results in more reward, and a negative value indicates that decreasing the corresponding probability value results in more reward.
We provide three methods for calculating the baseline 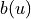 , which can be implemented by modifying the
, which can be implemented by modifying the baseline_strategy in oass.GradientCalculator.
"zero": No baseline.
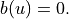
"random": Comparison with uniform random strategy (default value).
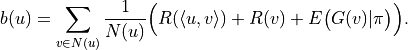
"self": Comparison with itself.
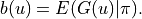
Extra Function
Among the many reinforcement learning methods such as A2C, PPO, etc., there is usually a 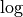 function, i.e.
function, i.e.
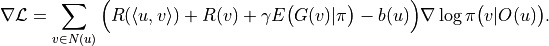
The reinforcement learning theoretical framework has its own set of theoretical support for this function, but in our experiments we found that the function sometimes speeds up convergence, but sometimes leads to model instability. Therefore we make it a customizable hyperparameter and do not use the function by default. You can change it by modifying extra_function in oass.GradientCalculator.
"none": No extra functions."log": Using function.